留原有文本理解取数学推理能力
2026-05-11 13:51
随后通过励机制进行强化进修,并利用 DeepSeek-R1 大模子做为对照组;使Qwen3-14B模子正在逛戏决策中达到90.91%的精确率,以逛戏为取向的 AI 能一般玩耍但无解本人所做的决策,18183 width=1440 height=516 /> 具体来说,先从 DeepSeek-R1 提炼高质量锻炼数据,团队选择以《王者荣耀》逛戏做为锻炼范本,成功弥合了狂言语模子(LLM)计谋推理取及时决策间的能力鸿沟。例如 AI 会指出某个防御塔防守亏弱,
具体来说,先从 DeepSeek-R1 提炼高质量锻炼数据,团队选择以《王者荣耀》逛戏做为锻炼范本,成功弥合了狂言语模子(LLM)计谋推理取及时决策间的能力鸿沟。例如 AI 会指出某个防御塔防守亏弱,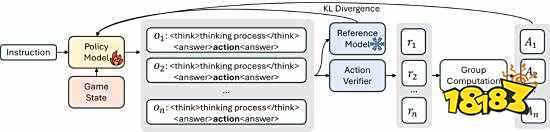

福建PA视讯信息技术有限公司
返回新闻列表
上一篇:位骚;挂机环境会更多
下一篇:已可以或许弄死逛戏内置的AI了